二分图
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
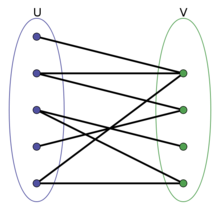
切记二分图中不存在顶点数为奇数的环路,通常可以使用染色法(该方法使用两种颜色,相邻的点标记不同的颜色)来辨别二分图。
匹配
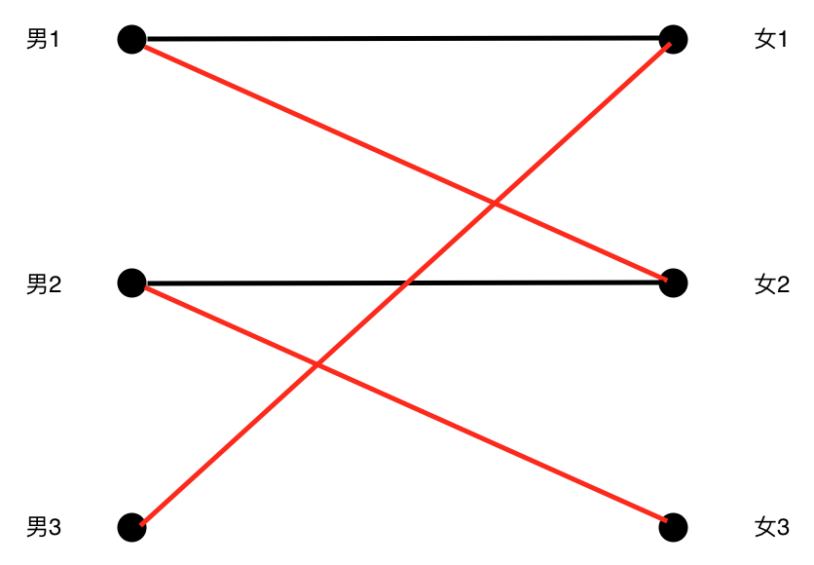
二分图的“匹配”是指一些边的集合,并且任意两条边没有公共点。下图中红色标注的即为匹配边。
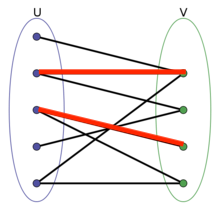
最大匹配
二分图的“最大匹配”,指的是二分图的所有匹配中边数最多的匹配。
交替路
从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边……形成的路径叫交替路。
增广路
从一个未匹配点出发,走交替路到达另一个未匹配点,并且非匹配边比匹配边多一条,那么这条路径叫增广路。如果用增广路中的非匹配边代替原来的匹配边,可以使匹配数量增加一个。下图中蓝色和红色标注表示当前匹配的一条增广路。
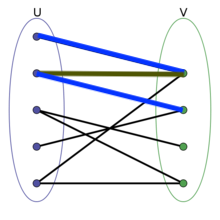
定理:一个匹配是最大匹配当且仅当它不存在增广路。
匈牙利算法
匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,并推动了后来的原始对偶方法。美国数学家哈罗德·库恩于1955年提出该算法。此算法之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家Dénes Kőnig和Jenő Egerváry的工作之上创建起来的。
若P是图G中一条连通两个未匹配顶点的路径,并且属于M的边和不属于M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广路径。
算法轮廓:
(1)置M为空
(2)找出一条增广路径P,通过异或操作获得更大的匹配M’代替M
(3)重复(2)操作直到找不出增广路径为止
举例说明
假如一个班上有3个男生和3个女生,每个男生都有喜欢的女生(可以有多个),每个男生只会和自己喜欢的女生谈恋爱,怎么撮合最多的情侣关系?
男1喜欢女1和女2,男2喜欢女2和女3,男3只喜欢女1。
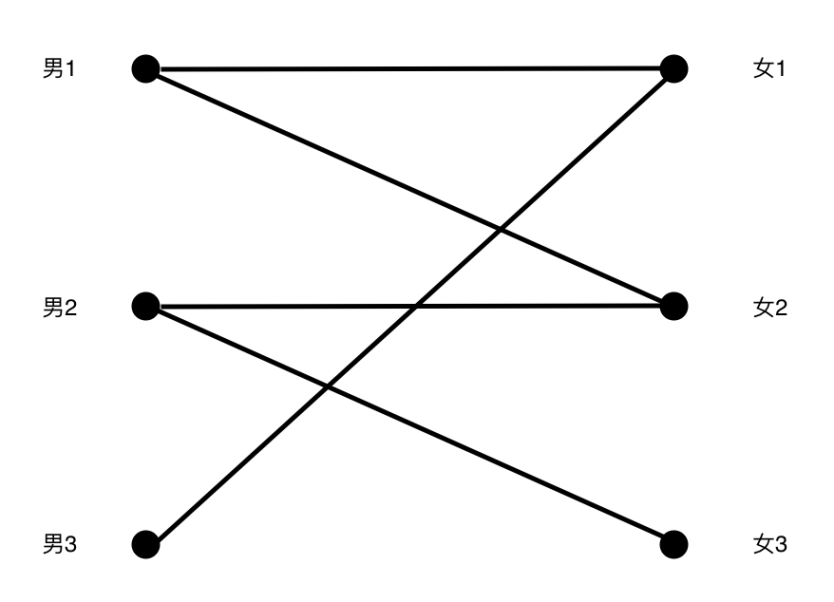
从男1开始配对,没啥难度,直接找到(男1,女1)。
PS:单独的一条非匹配边也可以叫做增广路。
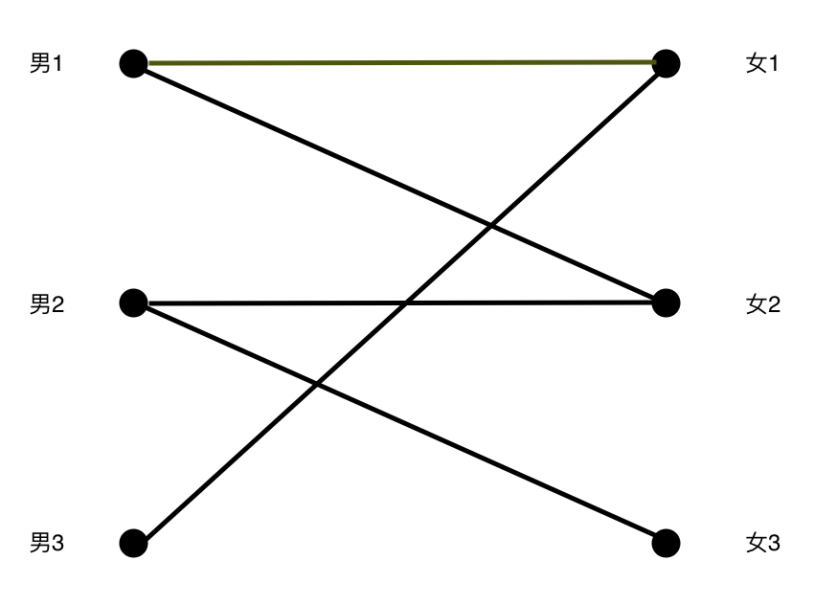
接下来看男2,也没啥问题,找到(男2,女2)。
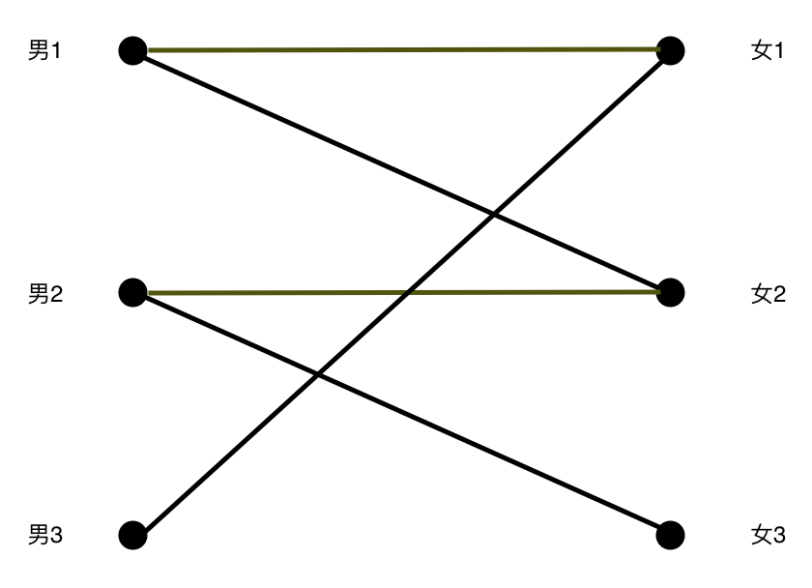
好了,轮到男3,但是他唯一的心动女生已经被选了。。。
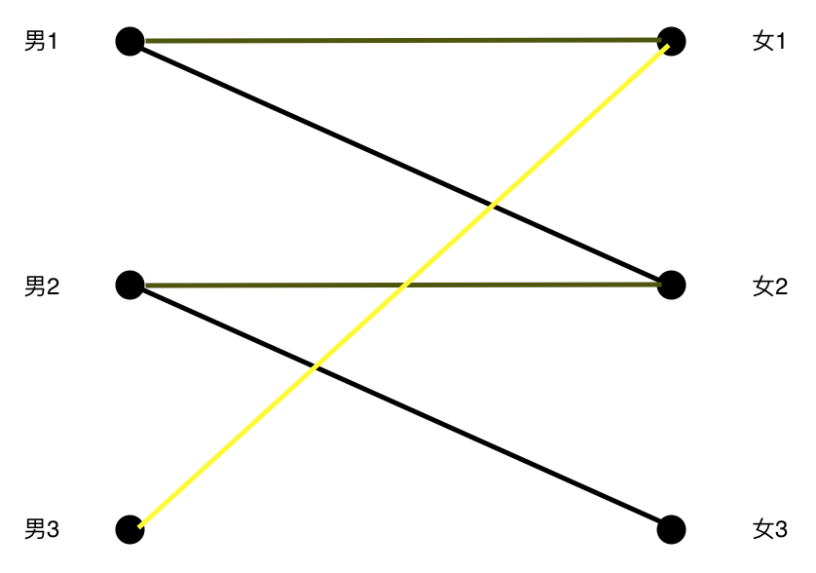
我们知道女1是和男1配对了,那么男1可以换一个妹子吗?
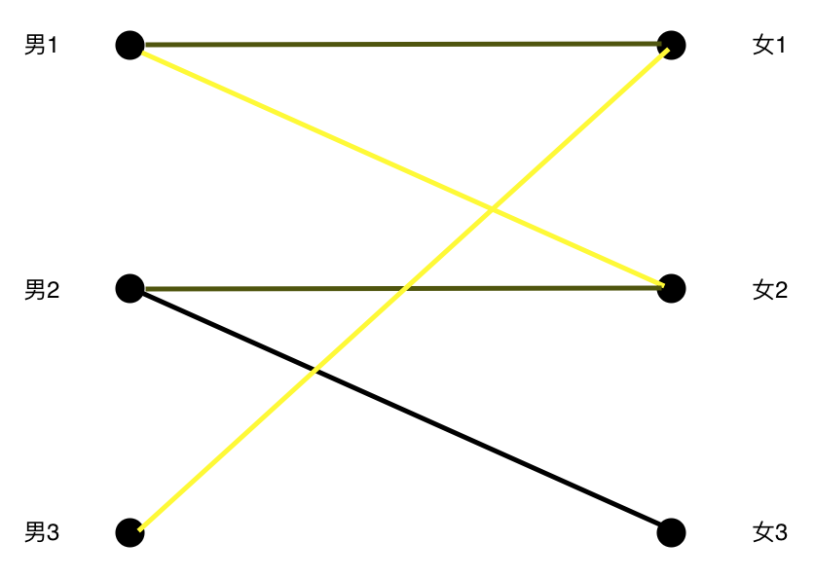
男1准备换女2的时候又发现女2也有主了,那么男2可以换一个妹子吗?
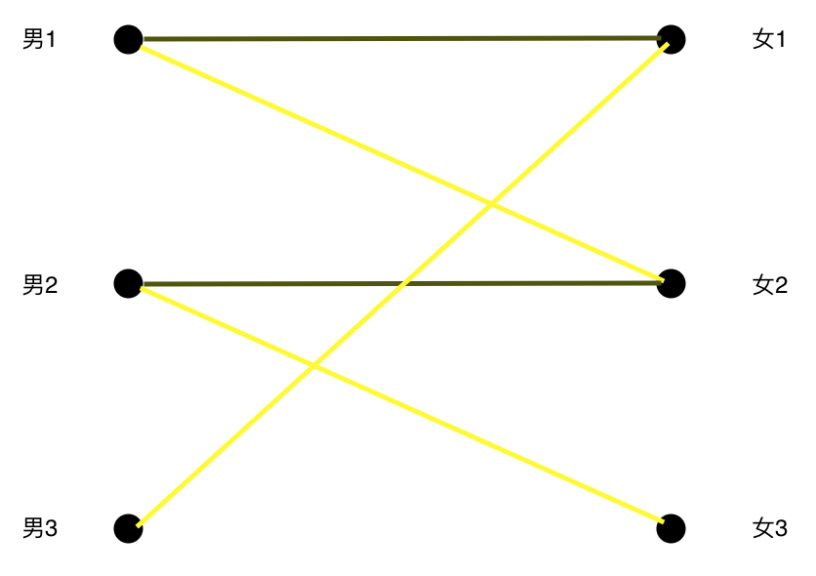
嘿嘿,原来女3这个妹子还没人选。
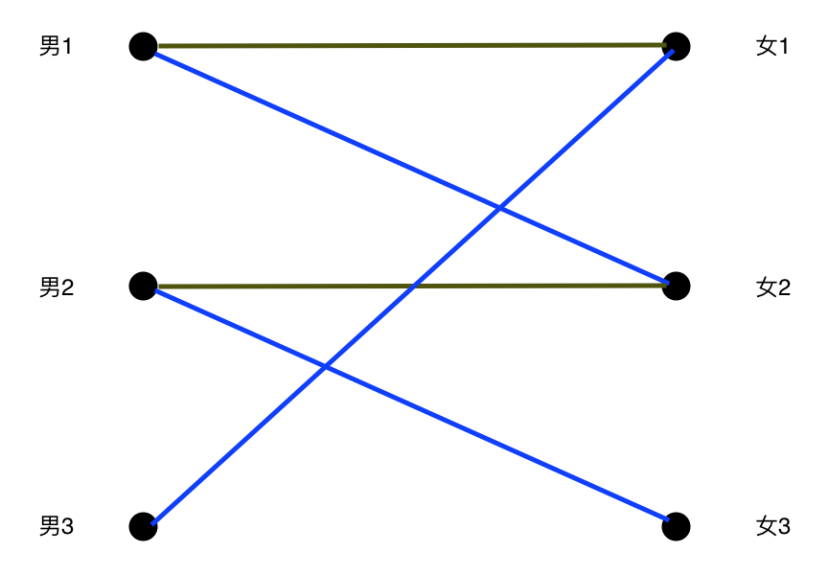
以上标黄线的图就是寻找增广路的过程,接着让非匹配边替换匹配边得到新的匹配集合。
模板代码
1 |
|
Hopcroft-Karp算法
HK算法的作用也是求二分图最大匹配,它在匈牙利算法的基础上做了一些改进,并且提升了效率。假设二分图的结点数量是n,匈牙利算法的时间复杂度为O(n^3),HK算法的时间复杂度为O(n^2.5)。
推导理论
本来如果只有原版英文资料我会做一些翻译,但是我找到了完整的中文版论文。
A n^2.5 algorithm for maximum matchings in bipartite graphs-[中文版, John E. Hopcroft & Richard M. Karp].pdf
其实看完整片论文我们只需要一个关键性的结论。
假设P是我们我们要找的增广路径,M表示匹配集合,s是我们所求的最大匹配基数(匹配对数)。
注意M0表示空集,P0表示M0的增广路径,|P|表示增广路径的长度,通过s次寻找增广路径就能找到最大匹配。有以下序列:
$|P_0|,|P_1|…|P_s|$
在这个序列中最多只有$2⎣ \sqrt{s}⎦+2$个不同的增广路径长度,并且相同长度的路径没有公共结点。
那么定义以下算法:

最短增广路径是相对于当前匹配集合M而言的,比如M是空集的时候,能找到的最短增广路径长度应该是1。
也就是说我们通过最多执行$2⎣ \sqrt{s}⎦+2$次上图步骤1即可找到最大匹配。
有了前面匈牙利算法的基础,KM算法重点就是理解如何找到最短增广路径。
模板代码
1 |
|