前言
由于工作需要,最近在学习实时协同编辑相关的知识。我在分享会听大佬讲了两个理论,分别是OT(Operational Transformation)和CDRT。但是听的时候跟不上,无奈只能下来找时间消化吸收了。会后拿到了两篇博客,看完理解之后还是想翻译一遍,留个存档。(偷个懒,图片链接我用的原文博客中的,所以要翻墙才能看)
知识点
介绍
多群首节点(本文中我们说的群首节点是指一个接受数据修改请求的节点)分布式系统的自动解决冲突算法是一个相当有趣的研究领域。关于这一块有很多不同的方法和算法,都有自己的权衡处理。本文我们将会重点讨论OT技术,它的目的就是解决想谷歌文档或者Etherpad这类协同编辑应用中的冲突。
从发展的角度来看,协同编辑是一个艰难的任务,因为客户端可以同时对相同的文档部分作出修改。为了模拟实时响应,每个客户端都要维护一个文档的本地复制,否则客户端就必须等待与其他客户端的数据同步,这可能会消耗很长的时间。所以协同编辑最主要的问题是保证本地复制之间的一致性。所有复制都能汇聚成一个正确版本的文件(在某些时候我们不能要求所有复制都和原文件一样,因为编辑过程可能不会停止)。
谷歌文档早期版本
谷歌文档第一版使用了文件版本对比(其他类似的应用也是如此)。想象一下,我们有两个客户 — Alice和Bob,还有一份已经同步了的文档。当服务器收到来自Alice的改动,它会计算两个版本之间的差异,并且尝试合并这两个版本。然后服务端把合并后的版本发送给Bob。如果Bob自己有未发送的改动,他尝试将收到的服务端版本和自己的合并。然后重复这个过程。
很多时候这个方法并不太奏效。比如,想象一下Alice,Bob和服务端已有一个同步文档“The quick brown fox”。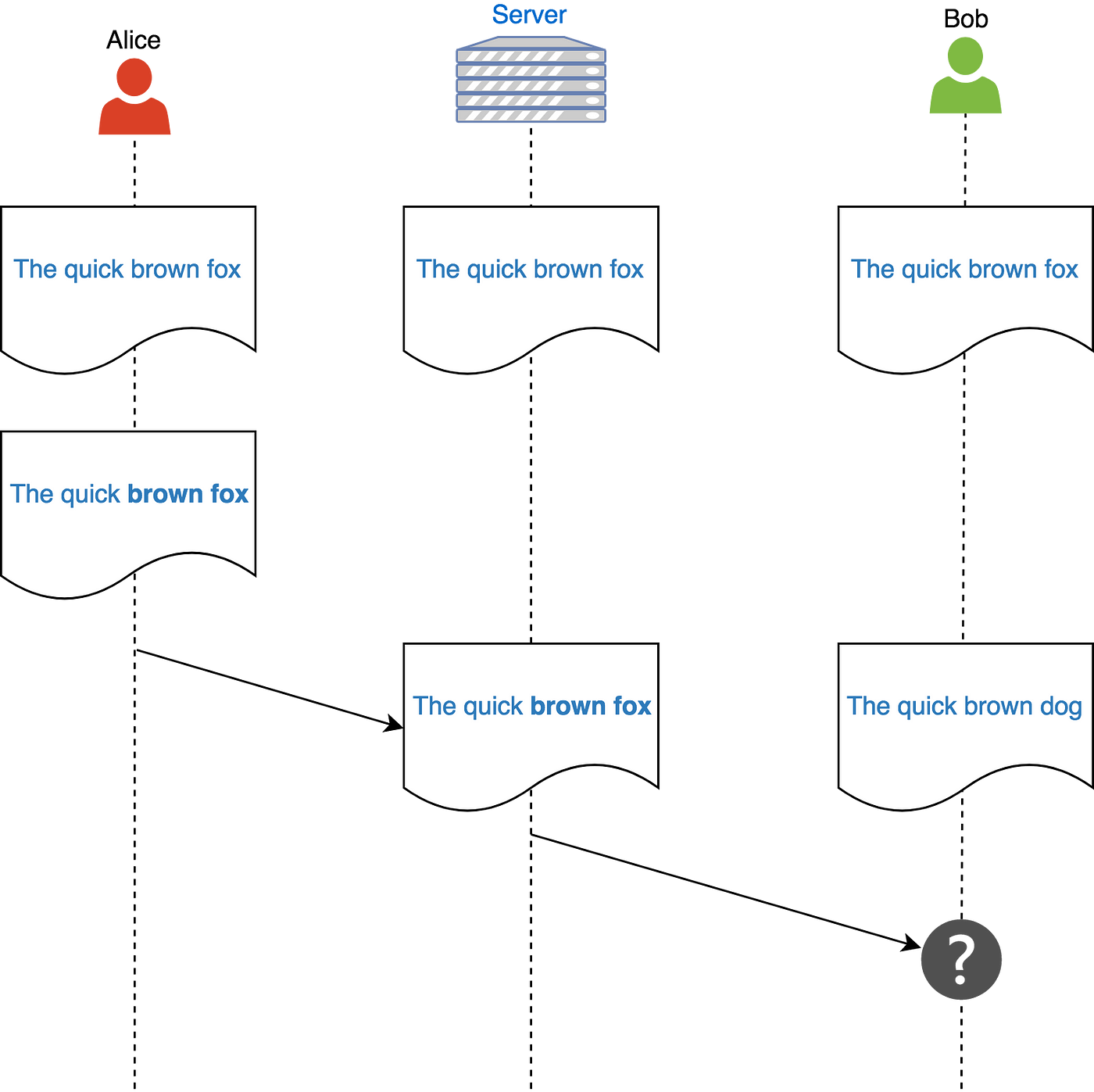
Alice加粗了单词“brown fox”,同时Bob将“fox”改成了“dog”。Alice的改动先传到了服务端,并且它使用之后再讲改动发送给Bob。合并后正确的结果应该是“The quick brown dog”,但是合并算法并没有充足的信息来执行正确的合并。从算法的观点“The quick brown fox dog”、“The quick brown dog”、“The quick brown dog fox”都是正确有效的结果。(在git中这种情况就需要我们手动解决冲突了)。所以这是最主要的问题 — 我们不能依赖这种方法来进行合并。
谷歌文档当前版本
当前版本的谷歌文档采用了另一种方法 — 一位文档被存储为一个操作序列,这些操作按照顺序(这里我们称之为全序)执行而不是比较文档版本。
好了,现在我们需要知道什么实用应用这些改动 — 我们需要一个合作协议。在谷歌文档中所有的操作分为3中类型:
- 插入文本
- 删除文本
- 改变样式
当你编辑一个文档时所有的改动都会按照这三种类型加入到改动日志中,当你打开一个文档所有日志中的改动又会重现出来。
(第一个(公开的)谷歌OT支持的项目是Google Wave,它的操作集合也更为丰富)
举例
让Alice和Bob从一个同步文档“LIFE 2017”开始。
Alice将2017改成2018,它产生了两个操作: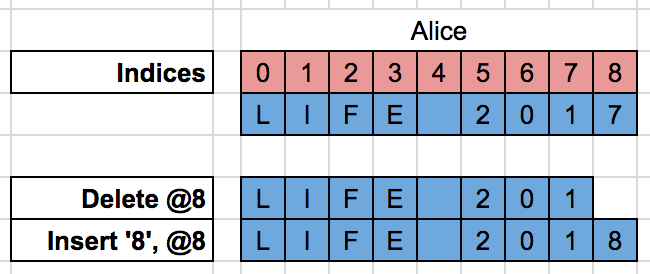
同时Bob将文本改成了“CRAZY LIFE 2017”: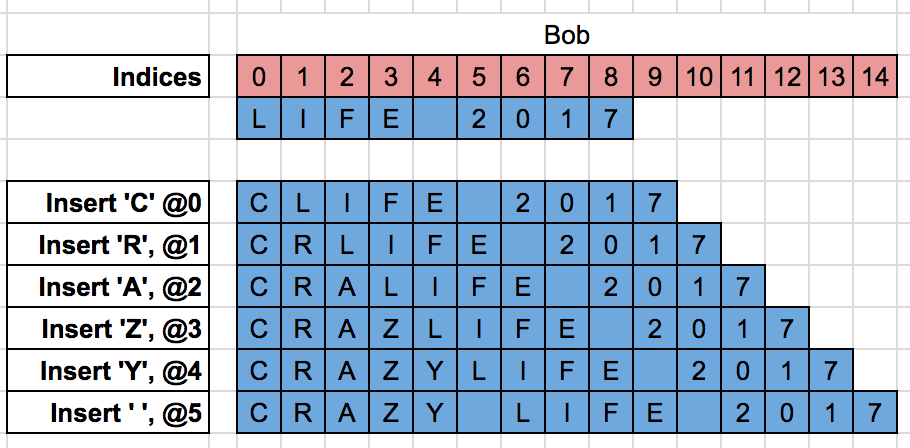
如果在接收到Alice的删除操作后直接应用,那么他就会得到一个错误的文档(实际上应该是数字7被删除)
Bog需要根据他的本地改动来转变删除操作,得到文档的正确形式:

现在就完美了。
为了更正式一点,让我们考虑下面的例子: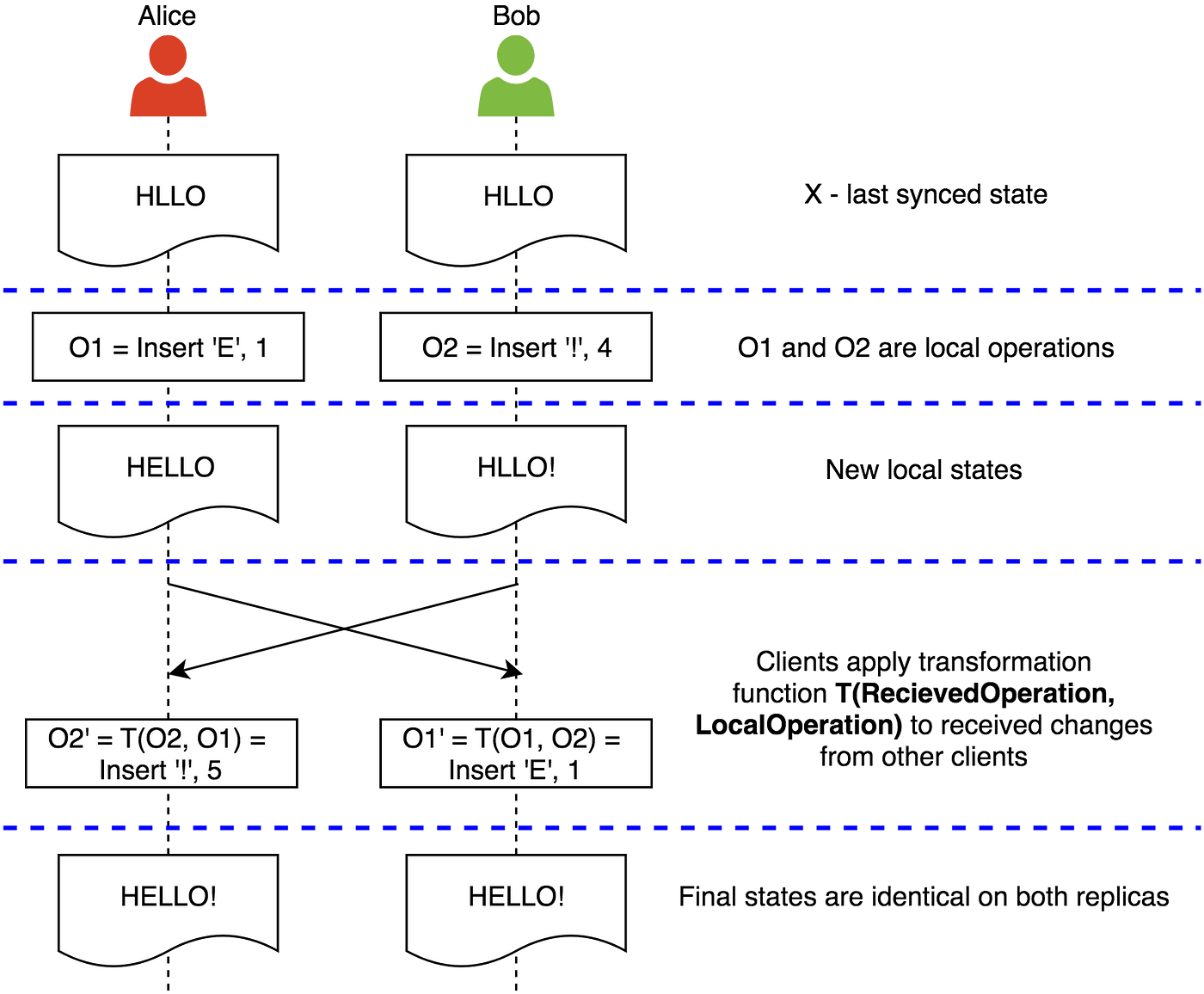
那么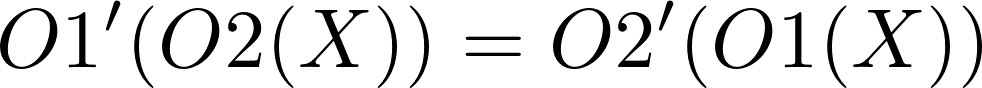
瞧!上述的算法就是Operational Transformation(操作转换)
操作转换
一致性模型
有一些一致性模型被开发出来保证OT的一致性。
让我们来看看其中一个 — CCI模型
CCI模型包含以下属性:
收敛:所有相同文档的副本在执行完所有操作后都会相同
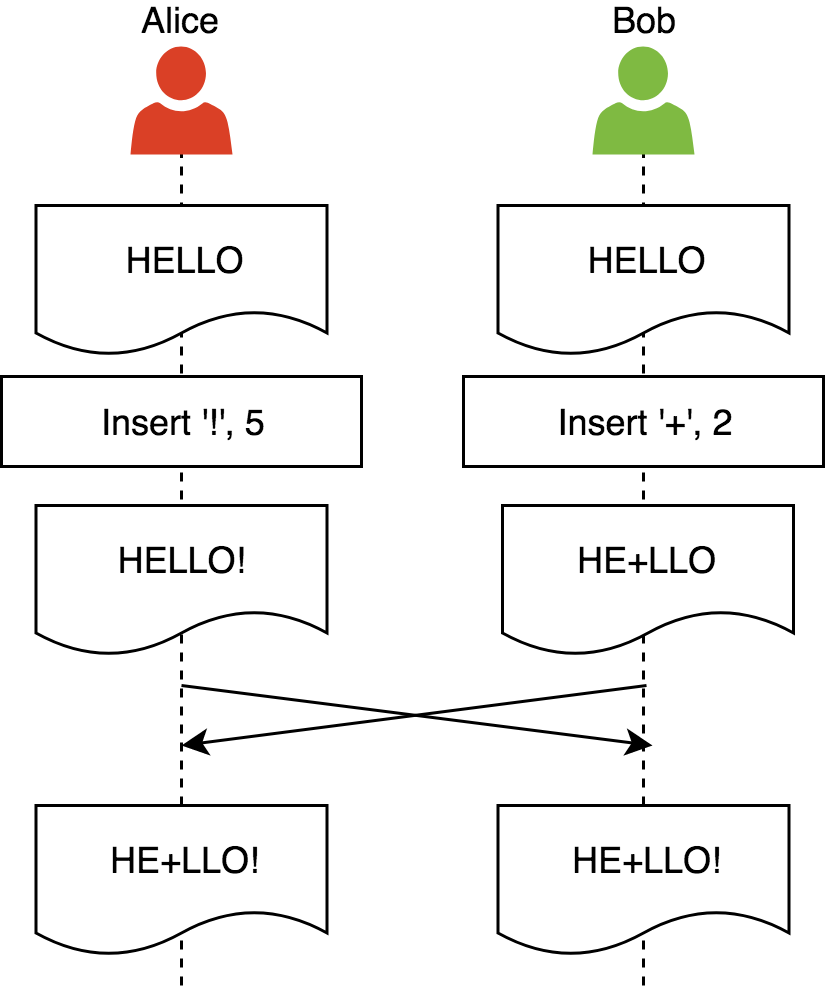
Alice和Bob从同样的文档开始,然后他们都做了本地改动,副本就会有偏差(这样达成了快速响应)。收敛属性要求Alice和Bob在接受到改动后看到的是同样的文档。意图保留:保证执行一个操作后对于文档的影响要和这个操作的意图一致。操作的意图可以解释为它的执行对所创建副本的影响。
让我们来看一个违背这个属性的例子: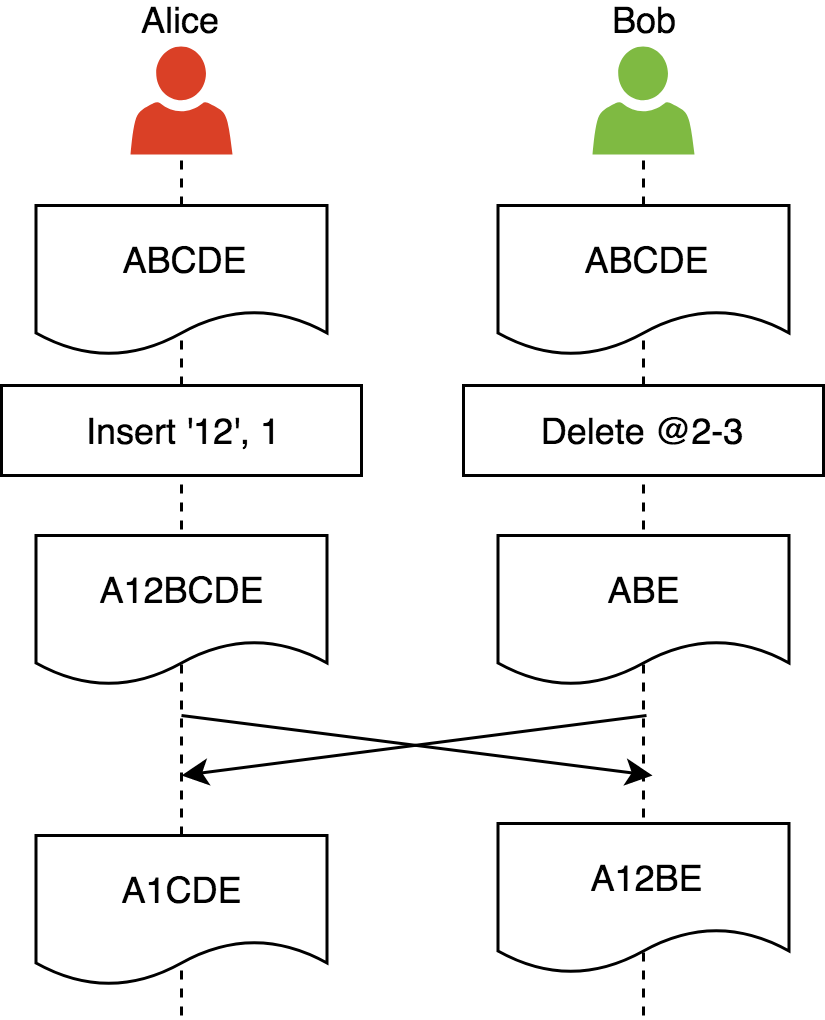
Alice和Bob从同样的文档开始,然后做他们的本地改动。Alice的操作意图是在位置1插入‘12’,而Bob的操作意图是删除‘CD’。同步之后Bob的操作意图就被破坏的。我们也观察到副本之间出现了分歧,但是这并不是意图保留属性的要求。练习:这个例子正确的结果应该是什么?(A12BE)因果关系保留:在协作过程中操作必须根据他们的自然的因果关系顺序执行(根据先行发生关系)。
让我们来看一个未被这个属性的例子: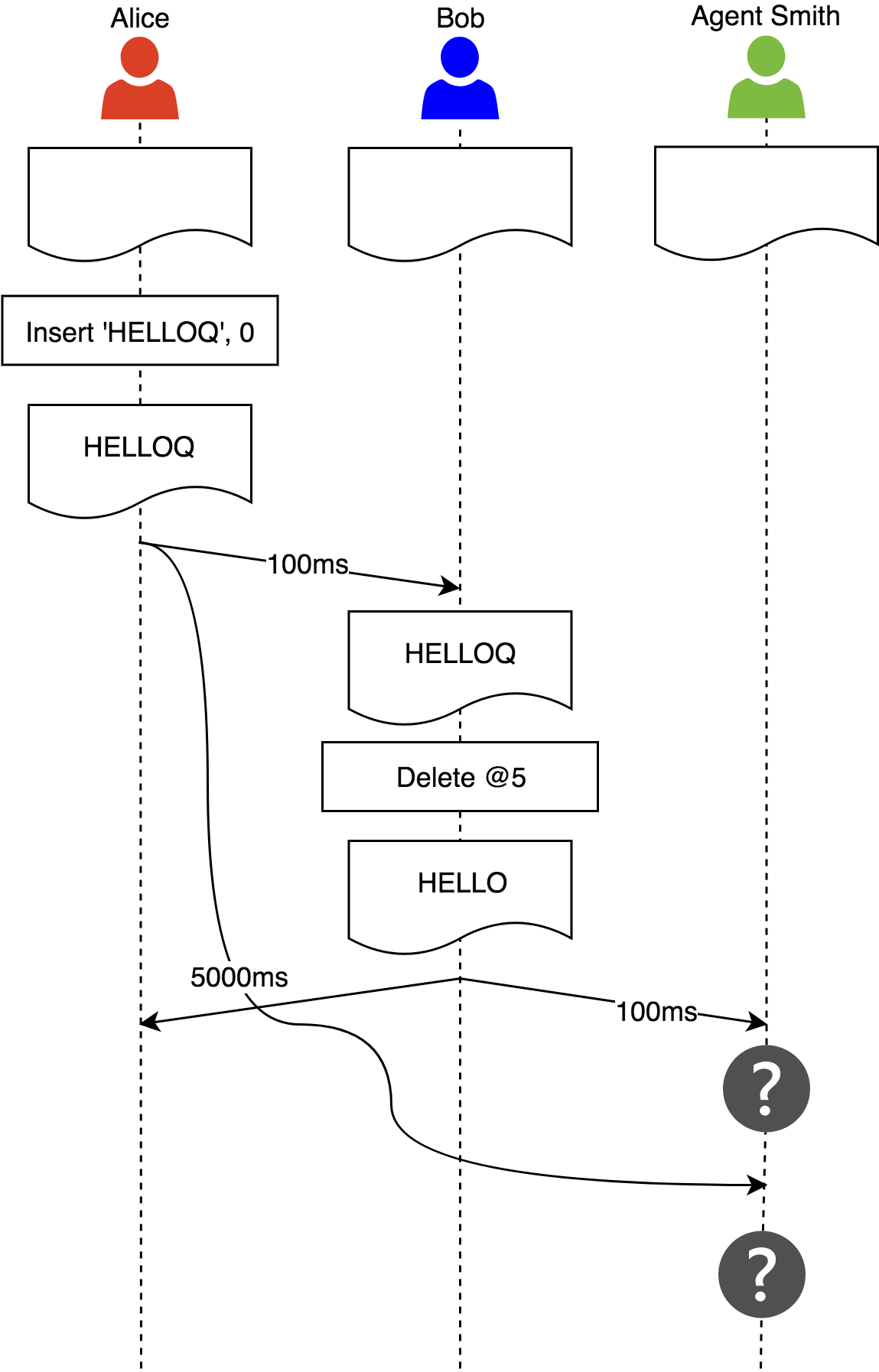
Alice、Bob和经理Smith从同样的文档开始。Alice做了她的改动并且发送到了其他客户端。Bob先收到了,然后纠正了拼写错误后把这个改动发送给其他客户端。由于网络延迟,经理Smith先收到了Bob的改动,删除了一个他的副本不存在的符号。
OT不能保证这个属性,所以像Vector clock这样的算法就派上用场了。
OT的设计
有一种OT的设计策略可以分为3个部分:

- 转换控制算法:作用是决定一个操作(转换的目标)是否准备好做转换,哪个操作(转换的参照)应该作为转换的对比,转换应该按照什么样的顺序实行。
- 转换函数:作用根据一个参照操作的影响对目标操作进行实际转换。
- 属性和条件:定义转换控制算法和函数的关系,作为OT算法的正确性的标准。
转换函数
转换函数可以分为两种类型:
- 向前包含转换:在执行$O_b$之前先转换$O_a$,而且$O_b$的影响会包含在转换中(比如两个插入操作)。
- 向后排除转换:在执行$O_b$之前先转换$O_a$,但是$O_b$的影响不包含在转换中(比如删除之后再插入)。
这里有一个转换函数的例子,它的作用于字符变动:
1 | Tii(Ins[p1, c1], Ins[p2, c2]) { |
谷歌文档的合作协议
让我们来看看谷歌文档合作协议的细节部分。
每个客户端维护以下信息:
- 上一个同步版本(id)
- 所有未发送到服务端的本地改动(即将发生的改动)
- 所有发送到到服务端带还未确认的改动(已发送改动)
- 当前文档状态对用户可见
服务端维护以下信息:
- 收到到还未处理的改动(即将处理的改动)
- 已处理改动的日志(归档日志)
- 最后一次处理完改动后的文档状态
假设我们已知Alice、Server、Bob,他们从一个空的同步文档开始。
Alice打出了“Hello”: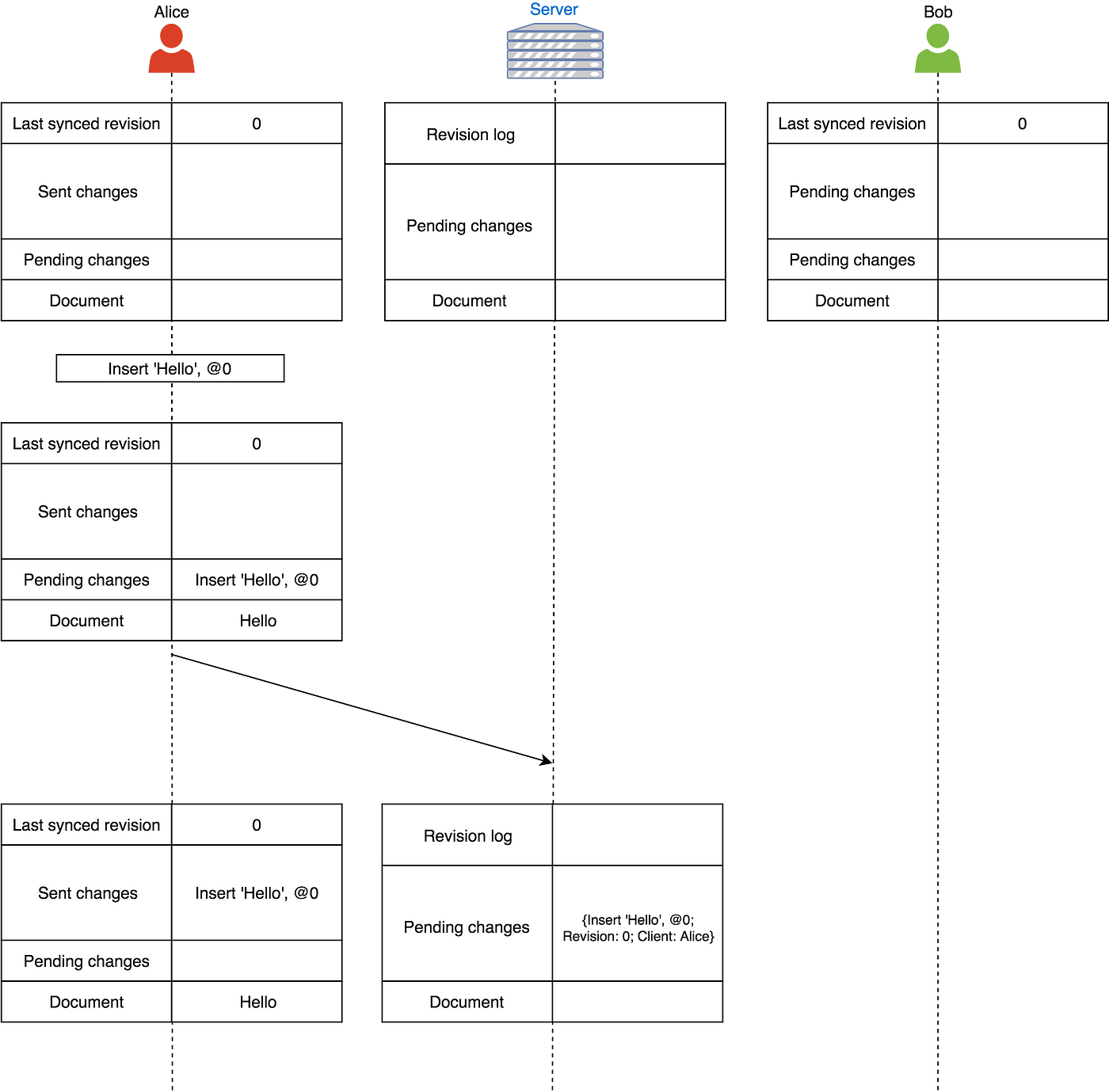
她的改动加入了即将发生的改动列表中,发送到服务端后加入到已发送列表中。
同时,Alice又加入了单词“World”。同时Bob在他的空文档中加入了一个“!”(他还没有收到Alice的改动):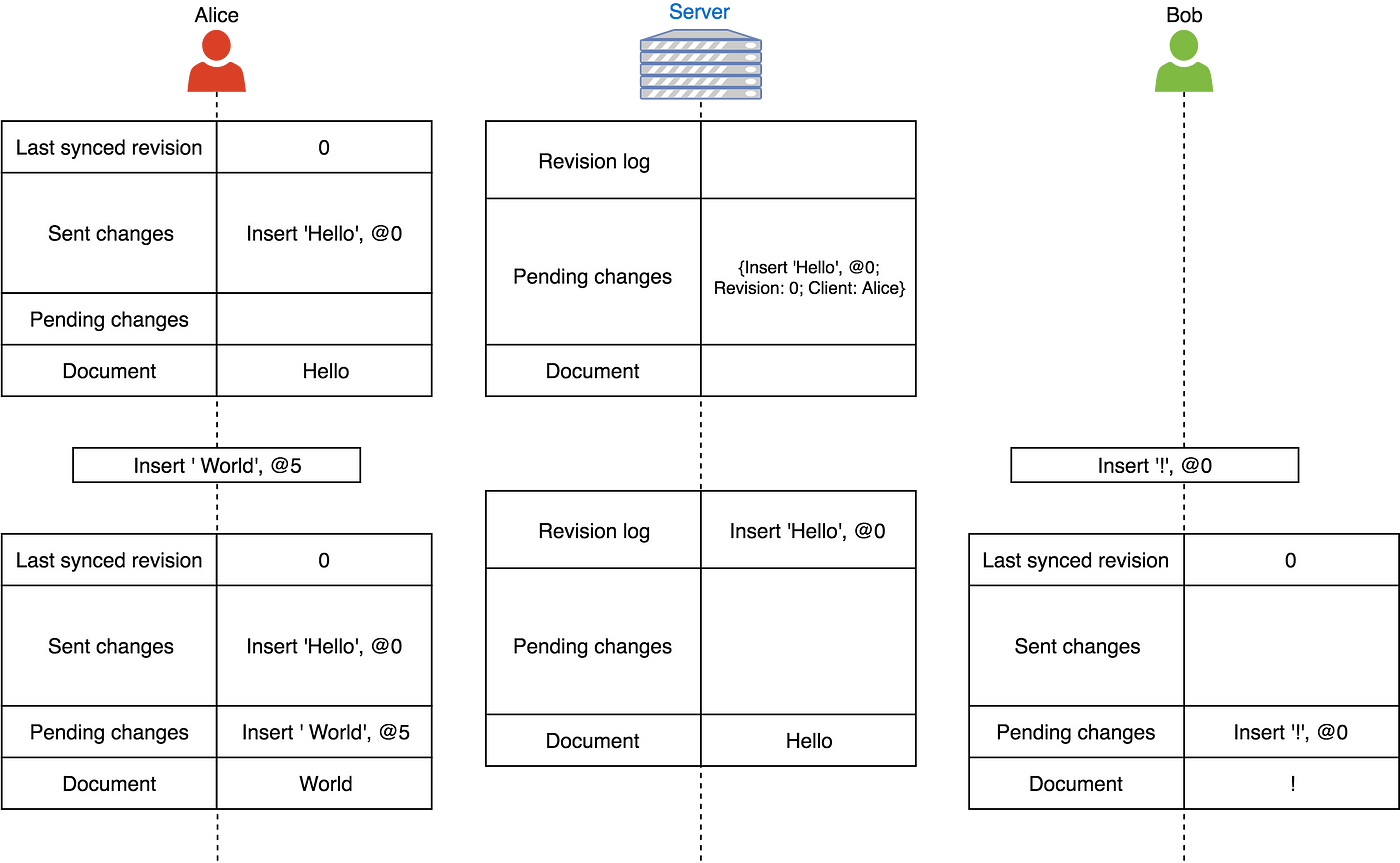
Alice的${Insert’World’,@5}$加入到了即将发生的改动中,但是这个改动并没有被发送,因为她的第一个改动还没有得到确认,我们一次只发送一个改动。而且还要注意服务端处理了Alice的第一个改动,并且把它加入到了归档日志。那么它发送一个确认信息给Alice,然后再将这个改动通知到Bob: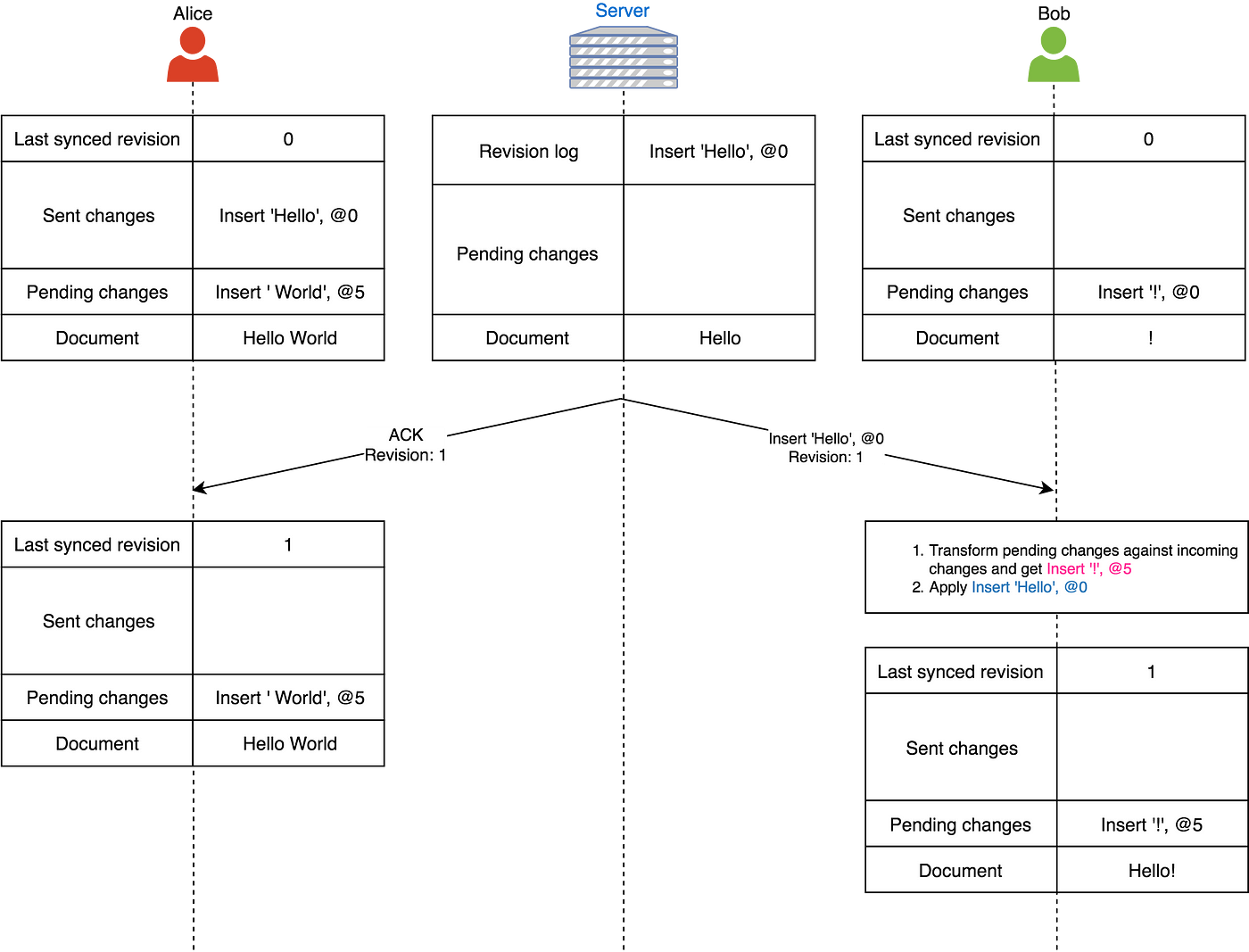
Bob接收到了改动,并且对它试用了转换函数,结果即将发生的改动索引从0变成了5。注意Alice和Bob都把他们的最新同步版本更新到了1。Alice最终将第一个改动从她已发送改动中移除了。
接着Alice和Bob又发送他们改动到服务端: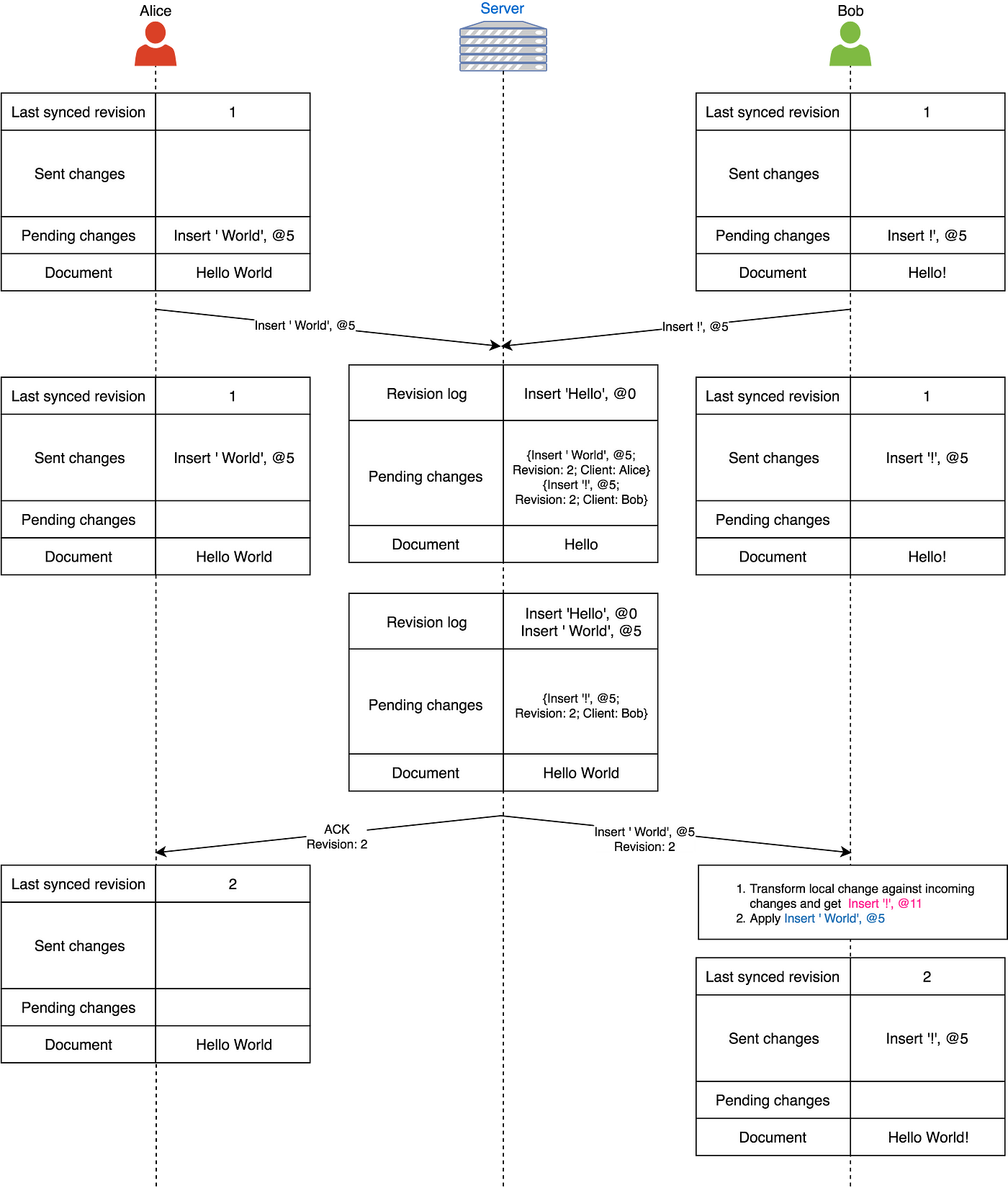
服务端先接收到了Alice的改动,进行了处理,然后发送一个确认信息给Alice,并且通知Bob。Bob使用了转换函数,他本地改动的索引变成了11。
接下来就到了重要时刻了。服务端开始处理Bob的改动,但是因为Bob的最新同步版本id已经被废弃了(2已经使用过了,实际上应该用3),服务端将这个改动根据所有Bob还不知道的改动做了转换,然后将最新同步版本改为了3。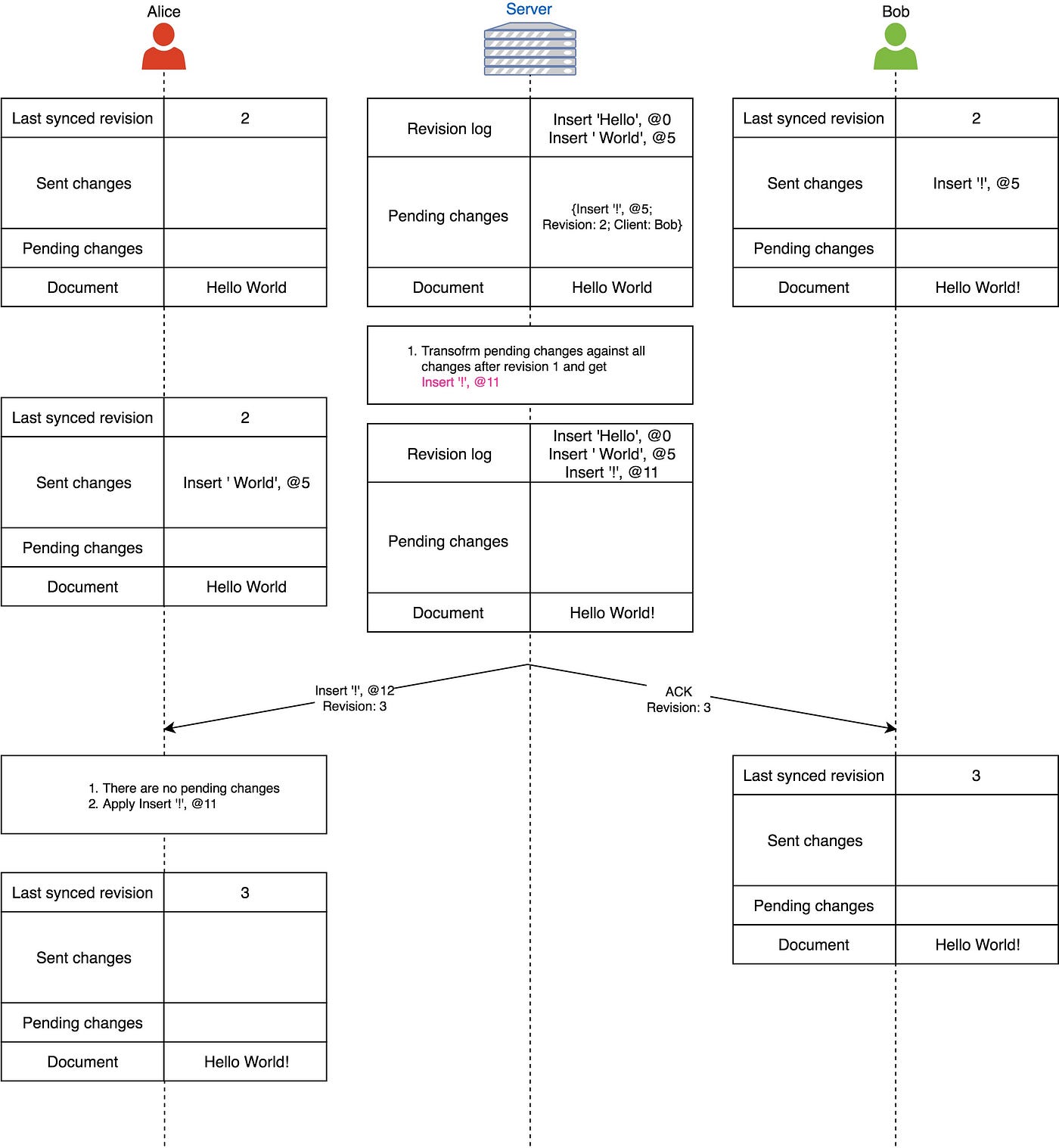
现在Alice的同步处理就完成了,Bob仍然需要接收服务端转换后的改动,然后发送确认信息。
Etherpad
我们来瞧瞧另外一个协同编辑应用,它也使用了OT技术 — http://etherpad.org
Etherpad使用的转换函数略微不同 — 他讲改动作为一个集合发送到服务端,形式如下:
其中:
- $p_1$ — 改动前的文本长度
- $p_2$ — 改动后的文本长度
- 如果$c_i$是数字或者区间,那么它表示原文档中保留字符的索引,如果$c_i$是字符或者字符串,那么它表示插入
比如:
- “” + (0 -> 5)[“Hello”] = “Hello”
- “Hllo World” + (10 -> 14)[0, ‘e’, 1–9, “!!!”] = “Hello World!!!”
通过把这些改动集合按照时间顺序应用于一个空文档就能得到正确的文档。
我们注意到服务端不能直接应用客户端的改动(虽然在谷歌文档中可能会这么做),因为文档的长度可能会不一致。比如,如果客户端A和B从同样的长度为n的文档X开始各自改动:
A: (n -> n_a)[…],
B: (n -> n_b)[…]
那么$B(A(X)$是不可行的,因为B要求文档的长度是n,在执行A后实际为n_a。为了解决这个问题Etherpad引入了所谓的合并函数,它让两个改动集合作用于同样状态的文档,计算出一个新的改动集合,它要求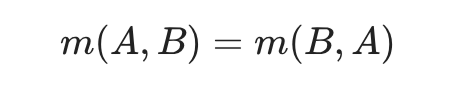
当客户端A接收到B的改动时,我们去计算m(A,B)就没什么意义了。因为m(A,B)适用的状态是X,而A现在的状态是A(X)。相反我们应该计算A’和B’,也就是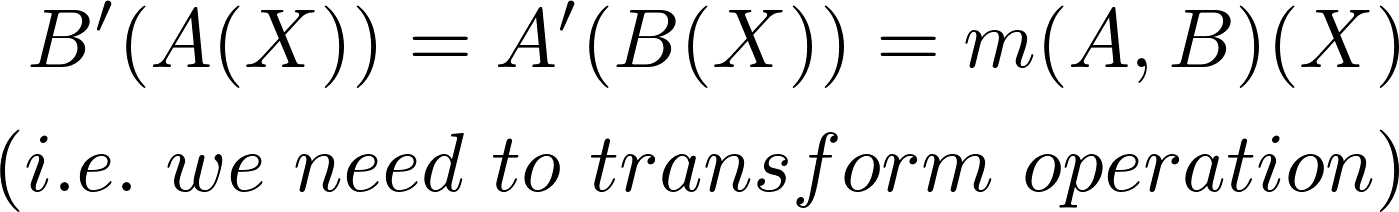
为了方便理解,我们定义函数$f$: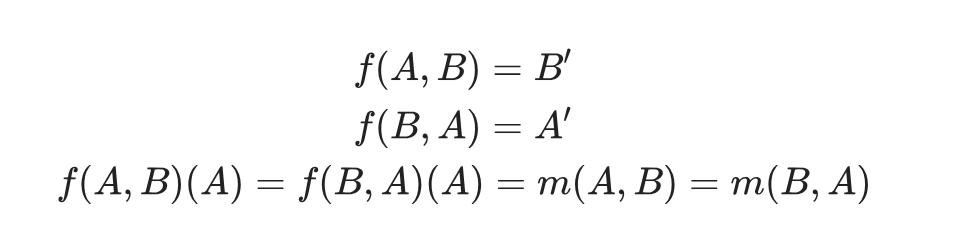
它根据以下算法构建(对于f(A,B)):
- 在A中的插入变成保留符号
- 在B中的插入保持不变
- A和B都有的保留符号也保持不变
案例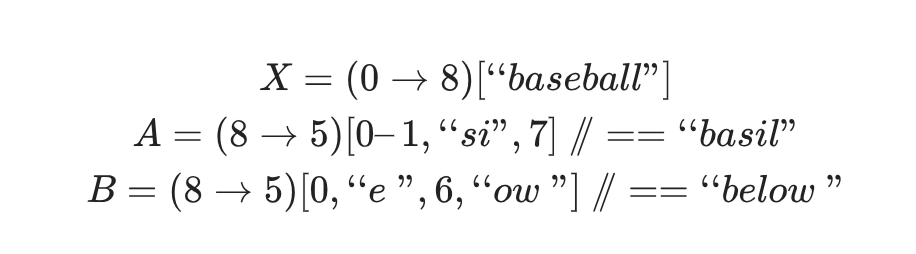
那么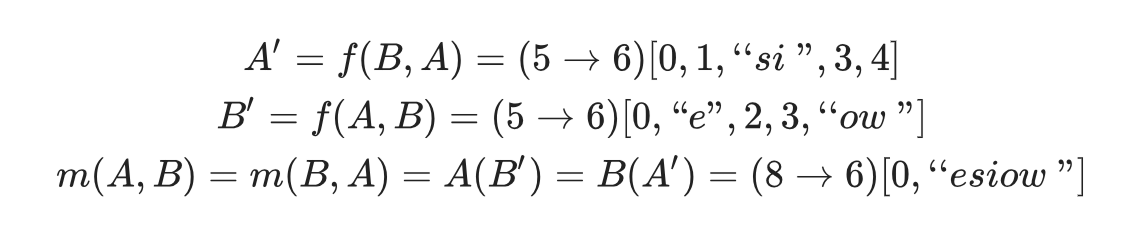
现在尝试去计算m(A,B)(X)的最终状态。(“besiow”)
OT的缺点
- 所有文档改动必须存储在一个操作集合中
- OT的实现是一个非常复杂的任务,应用字维基百科:
Joseph Gentle是前Google Wave的工程师,也是Share.JS library的作者,他这样写道,“OT这个功能做起来太操蛋了!”。现在有上百万个算法,衡量标准不一,大多数还局限于学术文章。这些算法都很晦涩,想要正确执行非常耗时。[…]Google Wave花了2年的时间来写,如果我们今天想要重写一遍,耗费的时间估计也不会比第一次少到哪儿去。